
Elasticsearch Client Programming - Perl
Since creating a log management system for the OSSEC HIDS with Elasticsearch, I have been busy applying this useful search technology in other projects. Elasticsearch is a marvelous system for ingesting streaming data that gets indexed on the fly and quickly searching your data.
The Elasticsearch community provides client libraries that expose their search API in several popular languages, including Perl and Python. This article is the first of a two part series where I show you how to write an Elasticsearch search client application in both of these languages, starting with Perl.
Install Eclipse for Perl
Even if you are an expert with Perl, I highly recommend writing your first Elasticsearch client using the Eclipse IDE, which has a Perl development plug-in that helps you not only step through your code but also see how Elasticsearch JSON is mapped to Perl data structures. If you don’t have a Perl environment for Eclipse then follow the steps in this section to install one. I’m going to assume you have an Eclipse IDE and Perl itself installed on your system.
The Eclipse Perl Integration project produces a plug-in for Eclipse that provides assistance for Perl development. You can install the plug-in by following these steps.
- Select Help > Install New Software… from the Eclipse main menu.
- Click on Add button to add the
Eclipse Perl Integrationupdate site. - Enter
Eclipse Perl Integration Updatesin the name field.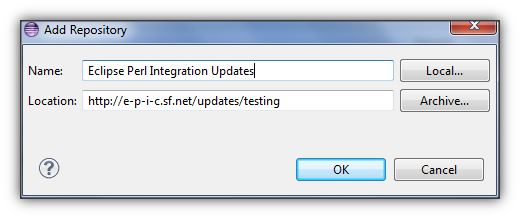
- Enter
hxxp://e-p-i-c.sf.net/updates/testingin the location field. - Click on OK.
- Click on the check box next to EPIC Main Components.
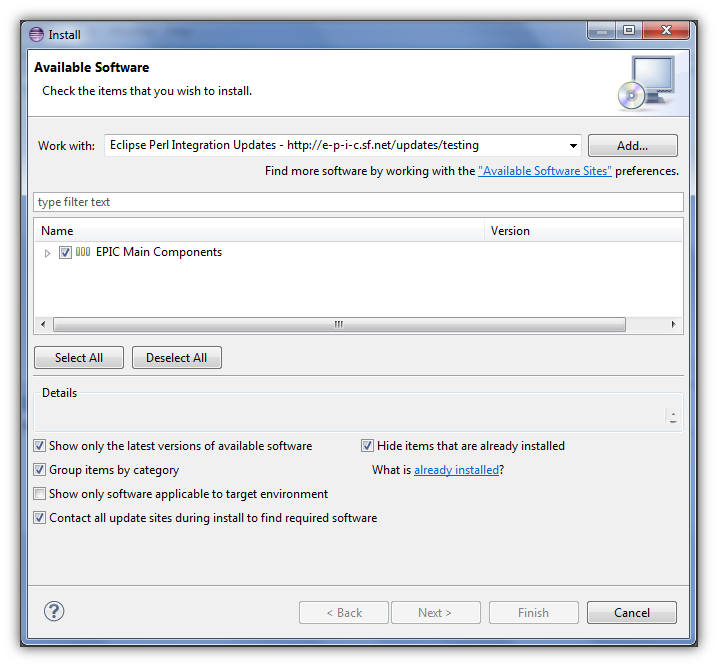
- Click on the Finish button. Note the button in this illustration is greyed out since I have l already installed the EPIC plug-in on my system, but for first installations the
To add the Elasticsearch client library for Perl on either Linux or Mac OS, simply run cpan as follows on the command line:
pcpan Search::ElasticsearchIf you are installing on Windows, just use the Perl Package Manager.
Connecting to Elasticsearch
Let’s say we have an Elasticsearch cluster comprised of indices that contain data collected from Twitter’s 1% sample feed. The tweets are collected in a new index each day. The format of the index name is tweets-yyyy-mm-dd. The server nodes that are exposed to clients is 10.1.1.1 and 10.1.1.2.
Now let’s do some programming. First create a new Perl project and client application file.
- Select File > New > Other…
- Enter the project name on the Select Wizard panel. Let’s call it
myPerlProject. - Select Perl > Perl Project.
- Click on Finish.
- Right click on the Perl project in the Navigation panel then select New > Other…
- Select Perl > Perl File
- Enter the file name on the Select Wizard panel. Let’s call it
tweet_search.pl. - Click on Finish.
- Double click on
tweet_search.pl, then start by entering the following code.
1
2
3
4
5
6
7
8
use Search::Elasticsearch;
$| = 1; # Flush to stdout immediately
my $es = Search::Elasticsearch->new(
nodes => [
'10.1.1.1:9200', '10.1.1.2:9200'
]
);
Lines [1-2] Include the Elasticsearch client module then set stdout to flush immediately, which is necessary when running Perl scripts in Eclipse.
Lines [3-8] Create an Elasticsearch client object. Specify the IP addresses and default Elasticsearch ports of the nodes to which the client will attempt to connect.
Do an Elasticsearch Query
Tweets are structured in JSON format as specified in Twitter’s documentation. The fields that will be retrieved from Elasticsearch include the Twitter user ID string, the date the tweet was created and the expanded URL – after unshortening – that was sent in the text of the tweet. Let’s take a look how that data will appear in an index.
Here is a partial JSON structure that shows the placement of the tweet fields that will be included in each query response, namely the ID string of the user who sent the tweet, the date the tweet was created and the expanded URL that was sent in the text of the tweet.
"coordinates": {},
"created_at": "2014-05-24T03:42:22.000Z",
"entities": {
"hashtags": [],
"urls": [
{
"url": "hxxp://t.co/9Bt38zRSMr",
"display_url": "Grd5.com",
"expanded_url": "hxxp://Grd5.com"
}
],
"user_mentions": [
{
"id": 868880934,
"name": "whatever",
"screen_name": "galatk123456"
}
]
},
"favorite_count": 0,
...
"user": {
"contributors_enabled": false,
"created_at": "2012-10-08T23:48:20.000Z",
"description": "whatever",
"favourites_count": 327,
"followers_count": 167,
"friends_count": 280,
"id_str": "868880934",
...Looking at this tweet snippet you can see that these fields are referenced by the JSON names as: user.id_str, created_at and entities.urls.expanded_url.
The query in this example will involve two indices, tweets-2014-04-12 and tweets-2014-04-13, looking for any expanded URL that comes from a Russian hosted domain *.ru. To do the Elasticsearch client search() method is called as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
my $rs = $es->search(
index => ['tweets-2014-04-12','tweets-2014-04-13'],
scroll => '60s',
size => 100,
search_type => 'scan',
body => {
'fields' => ['user.id_str','created_at','entities.urls.expanded_url'],
'query' => {
'wildcard' => {
'entities.urls.expanded_url' => '*.ru'
}
}
}
);
[Lines 1-5] One or more indices are specified in the index field which is an array of strings. The inclusion of the scroll and size fields creates what amounts to a cursor that indicates how many seconds Elasticsearch should cache results to be scrolled through and how many results are returned by each scroll operation, 100 tweets at a time in this case. Specifying search_type as ‘scan’ disables sorting of search results to improve the efficiency of scrolling through result sets.
[Lines 6-10] The type of query and fields involved are specified in the body field. The fields array includes the tweet fields that we want in the query response. The query does a wildcard search for expanded URLs that contain the characters .ru.
Retrieve the Query Results
The query results are retrieved 100 tweets at a time by successive calls to scroll() using the scroll ID returned from the original query.
1
2
3
4
5
6
7
8
9
my @tweets = ();
while (1) {
$rs = $es->scroll( scroll_id => $rs->{'_scroll_id'}, scroll => '60s' );
my $hits = $rs->{'hits'}{'hits'};
last unless scalar @$hits; # if no hits, we're finished
@tweets = (@tweets, @$hits);
}
[Lines 1-2] Create an array to hold all the retrieve tweets then retrieve successive sets of tweets in a while loop.
[Lines 3-4] Call scroll() with the _scroll_id field returned from search() to get a set of results. Elasticsearch returns query results in JSON object called hits that contains an array, also called hits, containing the search results. The hits array is extracted to another array to simplify referencing individual tweets. If the returned hits is zero, then break out of the while loop.
[Line 6 – 8] If scroll() returns 0 hits then break out of the loop. Otherwise add the current set of hits to the tweets retrieved so far and continue in the loop.
Display the Query Results
All that’s left to do is display the entire set of tweets returned. For queries where certain fields are specified, Elasticsearch conveniently returns just the fields specified, placing them in a JSON section labeled fields as shown here.
"hits": {
"hits": [
{
"_index": "tweets-2014-04-12",
"_type": "status",
"_id": "470047633969782784",
"_score": 1,
"fields": {
"user.id_str": [
"2481821394"
],
"created_at": [
"2014-05-24T03:44:23.000Z"
],
"entities.urls.expanded_url": [
"hxxp://www.chemfive.ru/news/toplivo_ehnergetiki/2013-07-26-55"
]
}
},
...To display the tweet fields, just loop through the @tweets array referencing the returned fields as shown here. Note that the strings are actually character arrays.
for (my $i = 0; $i < scalar @tweets; $i++) {
printf("%d\t%s %s\t%s %s\n", $i+1, $tweets[$i]{'_id'},
$tweets[$i]{'fields'}{'user.id_str'}[0],
$tweets[$i]{'fields'}{'created_at'}[0],
$tweets[$i]{'fields'}{'entities.urls.expanded_url'}[0]
);
}
printf("Total hits = %d\n", scalar @tweets);Using this client program you can experiment with other types of queries by simply changing the fields and body field contents.



Leave a comment