
XML Parsing with DOM in C++
Having the ability to parse XML files is a requirement for a lot of applications these days. XML is a standard format for exchanging data between programs and storing configuration data.
If you want to parse XML documents in C++ you can benefit from using an external library like the Xerces-C++ XML Parser. Xerces provides an elaborate, but somewhat complex API for navigating XML files. To simplify matters, I’ll describe a C++ class that encapsulate the Xerces calls to index and retrieve XML element values and attributes.
XML Parsing Models
XML Elements
XML documents consistent of elements that are denoted by beginning and ending tags. XML elements are of the general form:
<element attribute>
<element>value</element>
</element>where value consists of either a string value or additional XML elements. An attribute is a value associated with the given element.
Here is an example of an XML document that is intended to represent two books contained in a bookstore. The bookstore element contains two book elements each with a category attribute. Each book element contains fields to that describe the book.
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter and the Half-Blood Prince</title>
<author>J. K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>SAX Model
XML files can be parsed using two different XML models, SAX and DOM (Document Object Model). Parsing with SAX utilizes mechanisms where the XML document is traversed and as XML elements are visited the contents are passed back to the calling application. When the beginning and ending elements of a section, e.g. the book sections in the example XML, are encountered, the caller is notified so it can keep track of each section and so it knows that other elements will follow.
Since SAX parsing visits each element one at time, it is fast and does not make heavy demands on memory. It is also possible to process XML documents of arbitrary sizes. However, SAX requires the calling application to do all the heavy lifting when it comes to storing the XML field values.
DOM Model
With DOM parsing the entire XML document is read into memory and organized in the form of a tree as shown in the following diagram.
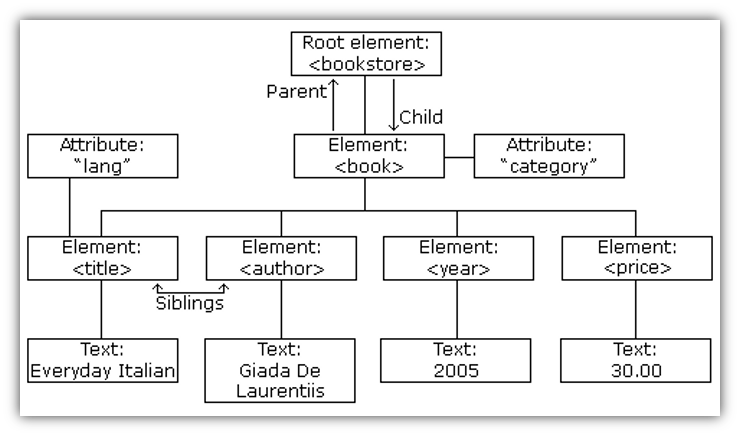
The root element is the bookstore and child elements are book. The bookstore is the parent element of the book elements. Each book element is the parent of four child elements: title, author, year and price.
When using DOM it is possible to index through each parent and child element, so the calling application does not have to maintain the document structure as it does with SAX.
The downside of using DOM is that the size of document you can parse with it is limited by the amount of memory an application has to work with and parsing is less efficient.
Xerces Installation
Before diving into the XML DOM parsing API, let’s go over how to install Xerces. You can get the Xerces library in binary form for various platforms, but I was built my example on MacOS so I elected to build from source.
- Download Xerces 3.1.1 from the download site.
- Place the tarball in your home directory or wherever.
- tar zxvf xerces-c-3.1.1.tar.gz
- cd xerces-c-3.1.1/
- ./configure
- make
- sudo su
- make install
This will place the Xerces headers and library in /usr/local on your system.
Xerces Platform Initialization
Before we do any parsing the Xerces the platform must first be initialized, which involves the following 3 steps:
- Call
XMLPlatformUtils::Initialize() - Create an
XmlDOMParserobject. - Create an error handler for the parser.
For convenience we’ll do these three steps in a single function call.
XercesDOMParser* parser = NULL; ErrorHandler* errorHandler = NULL;
void createParser()
{
if (!parser)
{
XMLPlatformUtils::Initialize();
parser = new XercesDOMParser();
errorHandler = (ErrorHandler*) new XmlDomErrorHandler();
parser->setErrorHandler(errorHandler);
}
}We only need one parser so createParser() does the platform intialization and parser creation just once. The error handler class is derived from the Xerces HandlerBase class as follows:
class XmlDomErrorHandler : public HandlerBase
{
public:
void fatalError(const SAXParseException &exc) {
printf("Fatal parsing error at line %d\n", (int)exc.getLineNumber());
exit(-1);
}
};When an exception in thrown within the Xerces platform it will be caught here and an error message will be displayed indicating the line number of the offending code.
XmlDOMDocument Class
The XmlDomDocument class encapsulates the Xerces DOM API. The class interface and definition are contained in the XmlDomDocument.h and XmlDomDocument.cpp files, respectively. Note that the createParser() code in the previous section is also defined in the XmlDomDocument.cpp file.
#include <xercesc/parsers/XercesDOMParser.hpp>
#include <xercesc/dom/DOM.hpp>
#include <xercesc/sax/HandlerBase.hpp>
#include <xercesc/util/XMLString.hpp>
#include <xercesc/util/PlatformUtils.hpp>
#include <string>
using namespace std;
using namespace xercesc;
class XmlDomDocument
{
DOMDocument* m_doc;
public:
XmlDomDocument(const char* xmlfile);
~XmlDomDocument();
string getChildValue(const char* parentTag, int parentIndex,
const char* childTag, int childIndex);
string getChildAttribute(const char* parentTag,
int parentIndex,
const char* childTag,
int childIndex,
const char* attributeTag);
int getChildCount(const char* parentTag, int parentIndex,
const char* childTag);
private:
XmlDomDocument();
XmlDomDocument(const XmlDomDocument&);
};Constructor
The constructor calls createParser(), which is defined in the XmlDomDocument.cpp file and visable outside this file, to initialize the Xerces platform then XercesDOMParser::parse() to parse the given XML and produce a DOMDocument object the pointer which is stored in the m_doc member variable. The XmlDomDocument default and copy constructors are declared private since we only want this object created one way, with a constructor that accepts an XmlDOMDocument pointer and the name of the XML file to be parsed.
XmlDomDocument::XmlDomDocument(const char* xmlfile) : m_doc(NULL)
{
createParser();
parser->parse(xmlfile);
m_doc = parser->adoptDocument();
}Destructor
Since the DOMDocument is adopted by the XmlDOMDocument, we must release the memory consumed by the document when XmlDOMDocument is destroyed.
XmlDomDocument::~XmlDomDocument()
{
if (m_doc) m_doc->release();
}Get Child Element Value
The XmlDomDocument::getChildValue() takes the name of a parent tag and the index of the parent tag in the XML file. For example, if I want to get the price of the Harry Potter book from the example XML file, the parent tag is book, the parent index would be 1 – like with C/C++ indexing starts from 0 – and the child tag is price.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
string XmlDomDocument::getChildValue(const char* parentTag,
int parentIndex,
const char* childTag,
intt childIndex)
{
XMLCh* temp = XMLString::transcode(parentTag);
DOMNodeList* list = m_doc->getElementsByTagName(temp);
XMLString::release(&temp);
DOMElement* parent =
dynamic_cast<DOMElement*>(list->item(parentIndex));
DOMElement* child =
dynamic_cast<DOMElement*>(parent->getElementsByTagName(
XMLString::transcode(childTag))->item(childIndex));
string value;
if (child) {
char* temp2 = XMLString::transcode(child->getTextContent());
value = temp2;
XMLString::release(&temp2);
}
else {
value = "";
}
return value;
}
[Lines 6-8] Instead of strings Xerces uses its own XMLString objects, so whenever we want to exchange strings with the platform we must convert from C++ strings to XMLStrings with a call to XMLString::transcode() which returns an XMLCh pointer when passed a pointer to a character string. The XMLCh pointer is then used in the call to DOMDocument::getElementByTagName() which returns a pointer to a DOMNodeList object. After we are done with the XMLString object we must release its memory back to the heap with a call to XMLString::release(). This a very common Xerces string usage pattern.
[Lines 10-14] In the Xerces DOM model an XML file is a collection of DOMNodeList objects each with a single root element that has 0 or more parent elements, retrievable by index, and each parent has 0 or more children, retrievable by child name and index. Getting back to our Harry Potter book example, the root element is bookstore, we want the second book parent referenced by index 1 and we want the first – at index 0 – child referenced by name price. DOMNodeList::item() returns a pointer to a the parent list object at the given index, which is cast to a DOMElement pointer. Similarly a pointer to the child element object for this parent is returned with a call to DOMElement::getElementsByTagName() the pointer to which is cast to a DOMElement pointer. The child element returned will be the one at the specified child index.
[Lines 16-25] If we get a non-NULL child element, its value can be obtained from a call to DOMElement::getTextContent() which returns a ponter to an XMLString then copied to a string object and returned to the caller. Otherwise the string with a NULL value is returned.
Get Child Attribute Value
Retrieving XML child attribute values is very similar to retrieving child element values, except that the attribute tag is also passed to the method. For example if we wanted the book category for the Harry Potter book, the parent tag is bookstore, parent index is 0, the child tag is book, the child index is 1 and the attribute tag is category.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
string XmlDomDocument::getChildAttribute(const char* parentTag,
int parentIndex, const char* childTag, int childIndex,
const char* attributeTag)
{
XMLCh* temp = XMLString::transcode(parentTag);
DOMNodeList* list = m_doc->getElementsByTagName(temp);
XMLString::release(&temp);
DOMElement* parent =
dynamic_cast<DOMElement*>(list->item(parentIndex));
DOMElement* child =
dynamic_cast<DOMElement*>(parent->getElementsByTagName(XMLString::transcode(childTag))->item(childIndex));
string value;
if (child) {
temp = XMLString::transcode(attributeTag);
char* temp2 = XMLString::transcode(child->getAttribute(temp));
value = temp2;
XMLString::release(&temp2);
}
else {
value = "";
}
return value;
}
[Lines 5-12] Retrieve the child element, if any, as before.
[Lines 14-20] This time get the specified child attribute value instead of the child value of the element.
[Lines 21-25] Return the attribute value or NULL string if the specified child or child attribute is not found.
Get Child Count
To get the number of elements contained under a given parent, we call DOMDocumentElement::getElementsByName() with the parent name, which returns a list of parent elements. We get parent element at parentIndex then call DOMDocumentElement::getElementsByName(), this time with the childTag. As before this gives us a pointer to a DOMNodeList from which we can get the child count directly with a call to DOMNodeList::getLength().
int XmlDomDocument::getChildCount(const char* parentTag, int parentIndex,
const char* childTag)
{
XMLCh* temp = XMLString::transcode(parentTag);
DOMNodeList* list = m_doc->getElementsByTagName(temp);
XMLString::release(&temp);
DOMElement* parent = dynamic_cast<DOMElement*>(list->item(parentIndex));
DOMNodeList* childList = parent->getElementsByTagName(XMLString::transcode(childTag));
return (int)childList->getLength();
}Test Application
Code
The test application is defined in the main.cpp file. It uses the XML file then gets all the books their attribute and child values then prints the values to stdout.
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <iostream>
#include "XmlDomDocument.h"
int main(int argc, char** argv)
{
string value;
XmlDomDocument* doc = new XmlDomDocument("./bookstore.xml");
if (doc) {
for (int i = 0; i < doc->getChildCount("bookstore", 0, "book"); i++) {
printf("Book %d\n", i+1);
value = doc->getChildAttribute("bookstore", 0, "book", i, "category");
printf("book category - %s\n", value.c_str());
value = doc->getChildValue("book", i, "title");
printf("book title - %s\n", value.c_str());
value = doc->getChildAttribute("book", i, "title", 0, "lang");
printf("book title lang - %s\n", value.c_str);
value = doc->getChildValue("book", i, "author");
printf("book author - %s\n", value.c_str());
value = doc->getChildValue("book", i, "year");
printf("book year - %s\n", value.c_str());
value = doc->getChildValue("book", i, "price");
printf("book price - %s\n", value.c_str());
}
delete doc;
}
exit(0);
}Build and Run
You can get the source code for the project from Github – https://github.com/vichargrave/xmldom. To build it just cd into the project directory and type make.
After building the test app run it as follows:
$ ./xmldomThe output will look like this:
Book 1
book category - cooking
book title - Everyday Italian
book title lang - en
book author - Giada De Laurentis
book year - 2005
book price - 30.00
Book 1
book category - children
book title - Harry Potter and the Half-Blood Prince
book title lang - es
book author - J. K. Rowling
book year - 2005
book price - 29.99


Leave a comment